Stable diffusion的开源生态为各种各样的辅助插件的开发提供了极大的便利,而这些辅助插件又可以为我们AI作画提供极大的便捷
1 插件界面介绍
Extensions 在扩展一栏
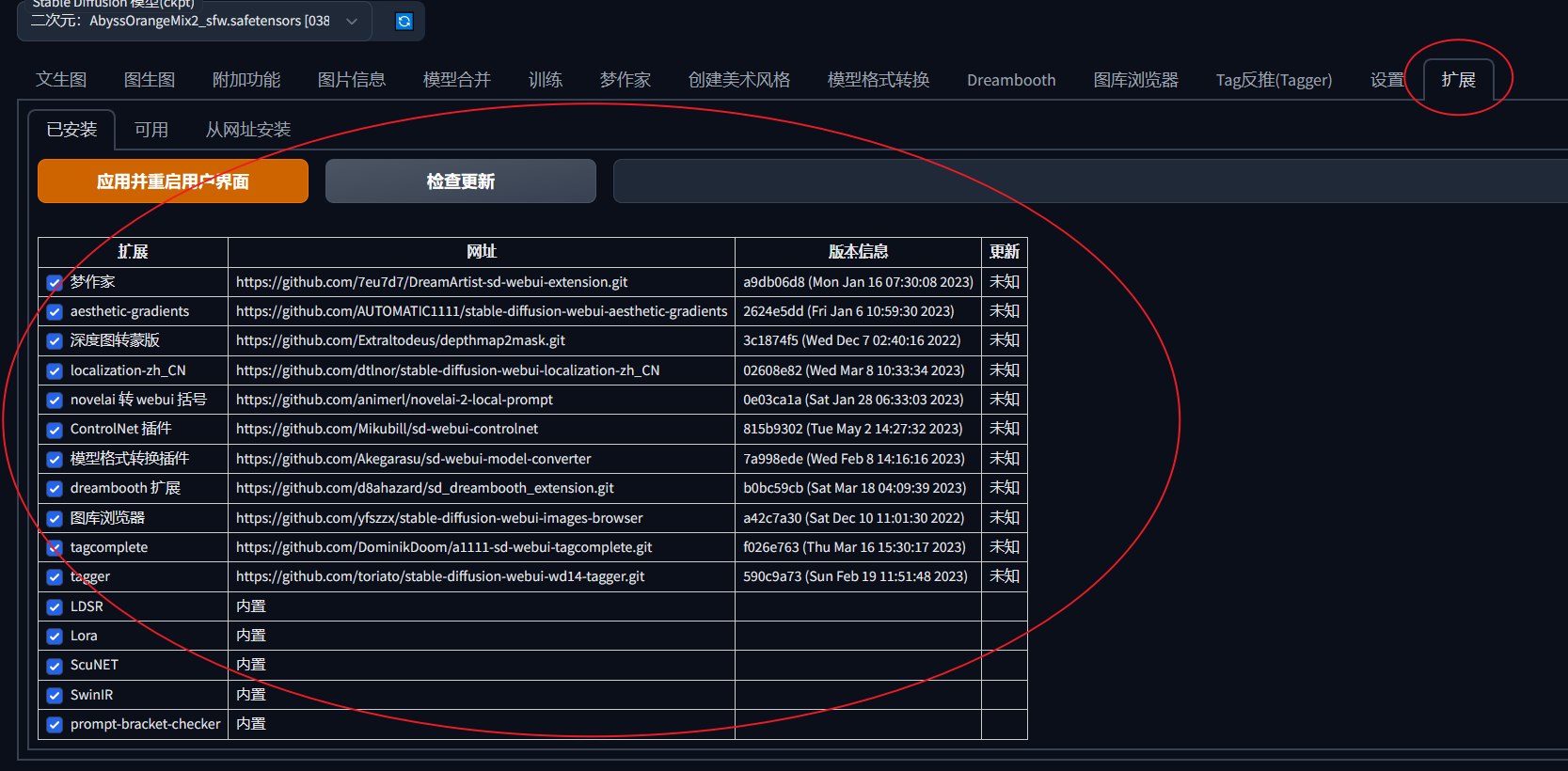
三个installed (已安装) Available (可用的)install from URL 从URL安装
如果是自己安装的sd,很可能刚开始的时候installed里面只有一些必要的插件,但是如果是一些大佬的整合包,则已经自带了一些插件
2 插件安装方式
1 Available(可用的插件)这里作者会把一些常用的插件记录在一个地址中,点击Load from,则可以加载出一系列详细的扩展应用清单
2 链接安装,复制代码仓库的地址,再点击安装也能实现一键安装
3 但上面两种方式都是借助git,因而可能会不稳定,所以还有最后一种方式,直接下扩展插件的代码包,然后送到Stable-diffusion根目录下的extensions文件夹里,然后点击应用并重启用户界面即可
3 新手插件
3.1 中文本地化语言包
搜索栏里搜索 zh
3.2 图库浏览器 image browser
有很多功能如收藏夹,筛选,查看图片信息等等
链接 https://github.com/yfszzx/stable-diffusion-webui-images-browser
3.3 提示词自动补全 tag autocompletion
链接 https://github.com/DominikDoom/a1111-sd-webui-tagcomplete.git
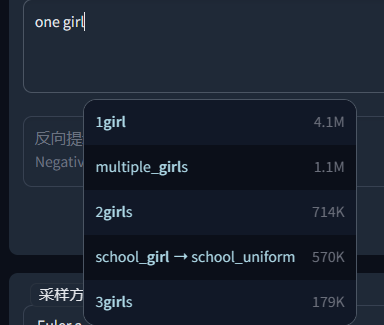
(1)他可以告诉我们AI可以更好理解的一些提示词
比如我们这里,输入one girl 这时候他下边自动提示1girl的写法,点击换用1girl会更好
(2)可以快速补全各类模型名称
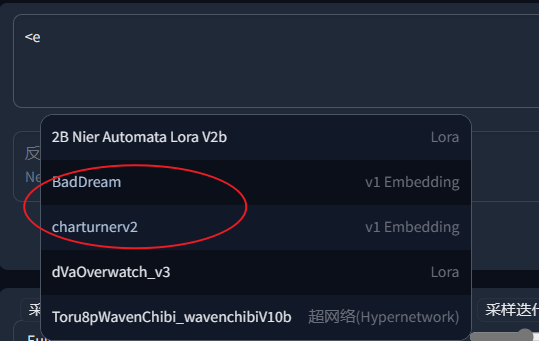
我们知道一些embeddings,lora模型需要特定提示词才能激活,但是那些提示词可能又臭又长记不住,怎么办,提示词插件来咯
输入:
<e:会展示 embeddings 名字<l:或者<lora:会展现 Lora 名字<h:或者<hypernet:会展现可选的 Hypernetworks
3.4 Tagger 提示词反推插件
链接 https://github.com/toriato/stable-diffusion-webui-wd14-tagger.git
上传图片,选择反推算法,一般维持默认即可,点击开始反推
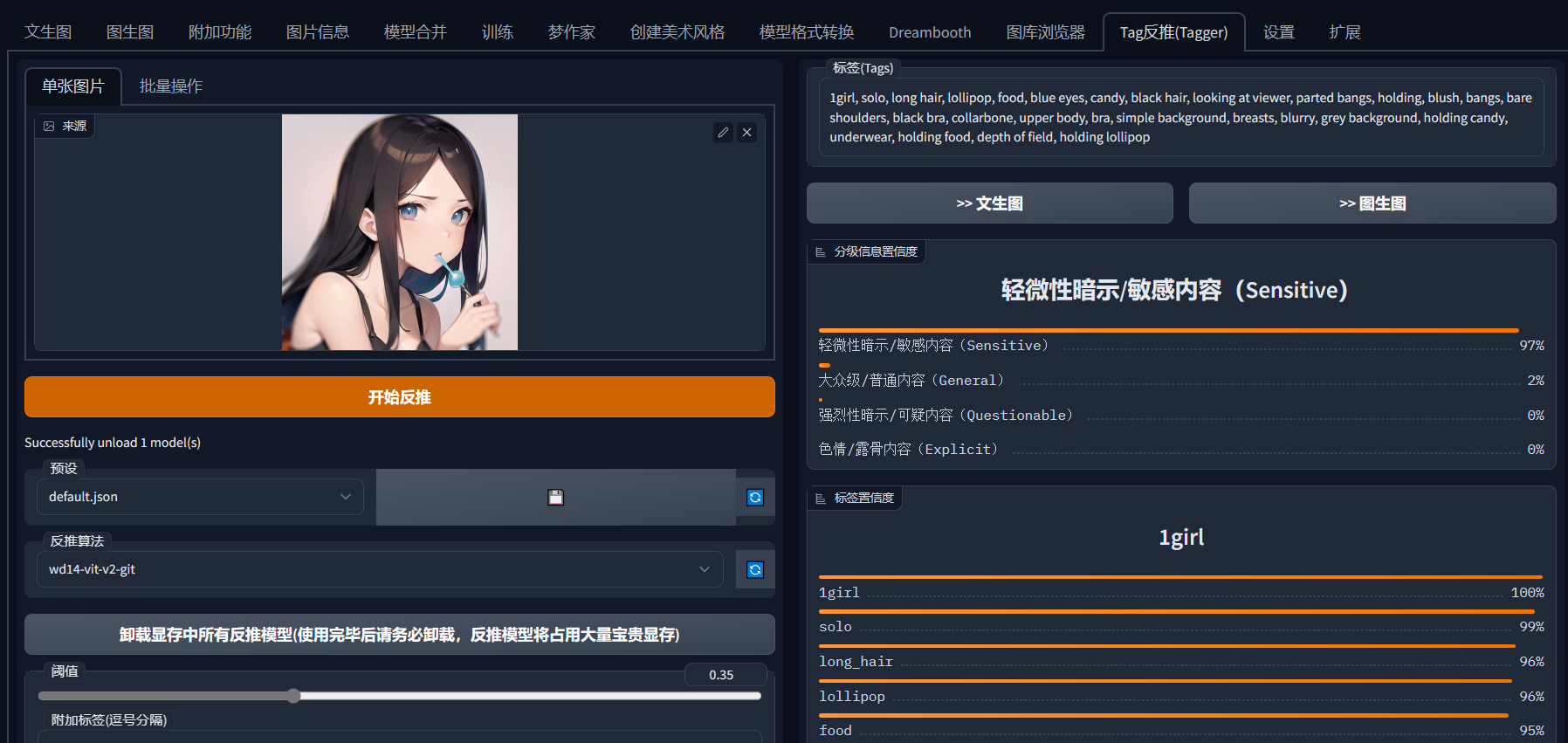
使用完后,点击卸载显存中所有反推模型
3.5 Prompt-all-in-one
Prompts 神器,它提供了自动翻译、历史记录和收藏等功能,支持多种语言,满足不同用户的需求。对英文不熟悉的用户,使用它,再也不用在翻译软件和SD之间反复横跳了。
4 进阶扩展
4.1提升画质
Ultimate Upscale 无损放大脚本
类似于SD 自带的放大,把图片拆成不同的块去放大
local latent Couple 局部隐空间
可以进行一些细节局部修饰,重新绘制
4.2 提示词
cutoff 解决提示词之间的相互干预
比如我们想让女生穿一个红色裙子,但是忽然发现红色到了帽子上等等其他地方
4.3 视频制作
infinite zoom 无限放大扩展
可以将图片无限延伸成为视频
Deforum
最近大火的可以将图片转出视频的插件,
4.4 精准绘图
骨架等识别
3d-open-pose-editor插件
Openpose-editor(骨架编辑)
用来编辑人体骨架,可以从已有照片中自动检测生成。结合controlnet,可以生成指定姿势的人物。可以大大提高出图的可控性。
4.5 抠图神器
Segment-anything(抠图神器)
5 自身内置
X/Y plot & Prompt matrix
prompt matrix和x/y plot多用于演示,都是生成一个有好几张图组成的多格图、当你想要对比一个或多个词(艺术风格、人物细节描述等等)对最后图片的影响(prompt matrix的使用场景)亦或是一个或多个参数的不同值下(不同扩散次数、不同cfg值等等)生成的不同图片对比结果(x/y plot的使用场景)



